Как мы научили YandexGPT пересказывать видео
Средний 14 мин Блог компании Яндекс Браузеры Машинное обучение *Искусственный интеллект Natural Language Processing *

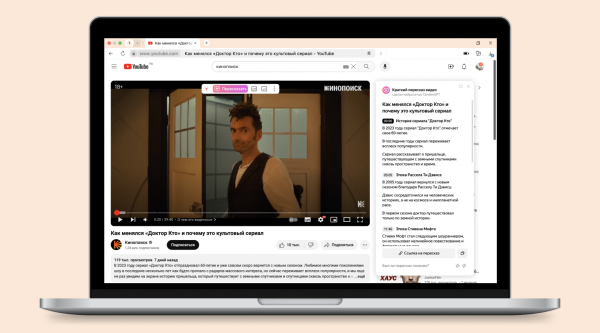
Порой бывает сложно перематывать длинный ролик в надежде найти хоть что-то интересное или тот самый момент из Shorts. Или иногда хочется за ночь узнать, о чём шла речь на паре научных конференций. Для этого в Браузере есть волшебная кнопка — «Пересказать», которая экономит время и помогает лучше понять, стоит ли смотреть видео, есть ли в нём полезная информация, и сразу перейти к интересующей части.
Сегодня я расскажу про модель, которая быстро перескажет видео любой длины и покажет таймкоды для каждой части. Под катом — история о том, как мы смогли выйти за лимиты контекста модели и научить её пересказывать даже очень длинные видео.
Содержание статьи:
Предыстория
Сразу же после запуска нашей дообученной модели YandexGPT, которая отвечала за суммаризацию статей, мы начали думать, какие возможности у нас появились вместе с новой технологией. Что ещё можно сокращать для удобства? Самой полезной идеей показалась суммаризация видео. Кроме того, нас об этом попросили буквально сразу, как только фича вышла в свет.

Видео — это совершенной другой формат. Здесь в приоритете аудио и видео, а не текст. При этом мультимодальные модели (модели, которые оперируют сразу несколькими видами информации, например изображениями и текстом) достаточно сложно завести.
С другой стороны, кажется, что тут не стоит изобретать чего-то сверхъественного: берём привычные пользователю субтитры (а это, по сути, и есть текст) и отдаём их модели. Технологий для получения субтитров много: есть решения от видеосервисов, например субтитры Ютуба, есть коммерческие или опенсорс-решения, например Whisper или наш SpeechKit. Готовая модель у нас тоже есть. Всё, готова суммаризация!
Конечно, данный подход имеет место, но у него есть существенные недостатки. Что мы получим, если отправим субтитры в модель? Кашу. Мы быстро выяснили, что модель YandexGPT, заточенная под суммаризацию статей, не особо подходит под нашу задачу. На это есть несколько причин:
-
В основном у видео линейная структура, плавно переходящая из одной темы в другую. Здесь важен таймлайн, а модель для статей его игнорирует, поэтому порядок тезисов не всегда с ним совпадает.
-
Качество субтитров не всегда на высоте. Какое бы ни было видео и какую бы технологию speech2text вы ни применяли, ошибок в конечном результате будет в разы больше, чем в статьях.
-
У видео разная продолжительность, а модель заточена под единый формат: она выдаёт примерно 5–8 тезисов, которых достаточно для принятия решения, стоит ли читать статью. Из-за этого у длинных двухчасовых видео получаются совершенно бесполезные суммаризации.
Резюмируя вышесказанное, получаем, что статейная YandexGPT не умеет работать с таймлайном и из-за своей специфики генерирует бесполезные суммаризации видео. Это явно не то, что мы хотели получить.
Ищем пользу
Мы начали с того, что выделили основные требования к суммаризации, учитывая особенности формата так, чтобы это стало полезно для пользователя. И вот что мы поняли:
-
Мы должны адаптироваться под длину контента. Для длинных видео — длинная суммаризация, для коротких — короткая.
-
Мы можем помочь в навигации. На многих видео нет разделения на части, а тех, у которых оно есть, крайне мало (чаще всего авторы сами прописывают таймлайны в описании или комментариях).
При этом первое требование скорее техническое, а второе продуктовое. О технических подробностях будет дальше, а продуктовое рассмотрим тут.
Для начала мы определили формат суммаризации. Получился такой:
{Заголовок} {Таймкод} {Тезисы для части} {Заголовок} {Таймкод} {Тезисы для части} {Заголовок} {Таймкод} {Тезисы для части}
Для пользователя он удобен тем, что решает сразу три задачи: структуризация контента, навигация, тезисное описание каждой главы.
Цели структуризации и навигации достигаются за счёт выделения чаптеров — оглавления видео с таймкодами. По нашим замерам, примерно у 90% видео нет чаптеров, которые бы разметил автор (эта цифра актуальна на общем потоке, если брать видео популярных видеоблогеров, процент видео с чаптерами выше). Поэтому такой формат суммаризации для пользователей — это возможность сэкономить время, лучше понимать, о чём пойдёт речь в видео, и перейти к нужному моменту, а также пропустить неинтересное или, наоборот, вернуться к интересному.
Кстати, мы рассматривали формат, где перед заголовком должны были быть эмодзи, но отказались от этой идеи. Хоть это и увеличивало эмоциональную оценку пересказа, но в итоге мы сошлись на том, что эмодзи скорее вредны, так как могут сместить фокус с более важных деталей краткого пересказа. Возможно, в будущем вернёмся к этой затее, но уже с A/B-тестированием — не будем гадать на кофейной гуще.
Формализация качества
Более важная деталь. Как оценивать качество модели? Логично, что оно будет определяться на основании двух основных критериев:
1. Качество выделения частей. В это входят такие вещи, как заголовок и таймкод.
2. Качество тезисов.
Кажется, что критерии просты, но каждый из них многогранен. Нам потребовалось достаточно много времени просто на то, чтобы попытаться формализовать, как выглядят хорошие часть и тезис.
Для начала определим, что такое хороший тезис. В первую очередь цель тезиса — не излагать ложную информацию. И, кажется, сразу стоит уточнить, что такое ложная информация: это значит, что суммаризация не должна противоречить первоисточнику (тексту, который пересказывают). Является ли информация глобально ложной — не столь важно.
Ещё важно учитывать не только тезисы по отдельности, но и в связке. Каждый из тезисов по отдельности может быть корректным, но если поставить их вместе, то получается что-то, что тяжело читать.

Первые эксперименты и тезисы, в которых прекрасно всё: здесь модель явно загаллюционировала и заглянула в будущее OpenAi, а ещё наглядно показала, как может выглядеть нелаконичная суммаризация с частыми повторами и зацикливаниями
Не менее важный критерий — тезисы должны быть полезными. Я попытаюсь выразить это в виде придуманного пересказа статьи «Топ-10 тестомесильных машин». Предположим, что модель ответила так: «Автор обсудил 10 тестомесильных машин, разобрал их плюсы и минусы и выразил мнение о том, какая из машин, по его мнению, лучше всего». Пользы здесь нет. И мы не хотим, чтобы наши суммаризации были похожи на что-то подобное, поэтому активно боремся с излишне обобщёнными пересказами с отсутствием конкретики.
В случае выделения чаптеров требования другие. У хорошего чаптера не обязательно должна быть конкретика в заголовке — главное избегать зацикливаний, повторных названий и стремиться к тому, чтобы всё было хорошо с точки зрения эстетики.
Второй более важный и комплексный аспект качества чаптера — корректный таймкод. Для нас важно, чтобы модель отдавала такой таймкод, чтобы он помогал навигации по видео, разделял его на равномерные куски и логически соотносился с теми тезисами, которые будут написаны далее.
Чем конвертировать видео в текст
Поиски пользы в целом никак не повлияли на основной алгоритм: берём звук из видео, преобразовываем его в субтитры и генерируем суммаризацию. Будем разбираться со всем по-порядку.
Чтобы получить субтитры, мы отталкивались от той же технологии Браузера, которая знакома пользователям по переводу видео. Однако в случае суммаризации мы адаптировали технологию под нашу специфику: здесь мы используем более быстрые модели, чтобы сократить время ожидания результата. Несмотря на то, что это решение снизило качество относительно большой модели, применяемой в переводе видео, на относительные проценты, мы получили ускорение распознавания в 5 раз.
Как решать задачи с помощью LLM
Поговорим немного об основах. В случае LLM есть три основных способа научить модель решать задачу с требуемым форматом:
-
p-tune,
-
LoRa,
-
fine-tune.
P-tune — если кратко, это автоматизированный подбор промпта (более детально об этом рассказал коллега в этой статье). Он работает эффективнее, чем человек, которого посадили подбирать удачный промпт. В целом это хороший подход, но в нашем случае он почти никогда не давал требуемых результатов с необходимым качеством. Сам подход не может именно научить модель: задача должна быть достаточно простой для модели или в каком-то виде присутствовать в обучении.
Для сложных задач интереснее LoRA и fine-tune. На практике разница между ними в максимальном качестве, которого можно достичь: у разморозки слоёв в fine-tune предел качества выше. Но давайте рассмотрим каждый подход подробнее.
У LoRA есть параметр — ранг. Чем больше ранг, тем более сложному навыку можно обучить модель. Но и тут есть свои нюансы. Мы проводили эксперимент с рангом LoRA и ростом качества в зависимости от него. Шаг ранга — степень двойки (4, 8, 16, 32, 64, 128, 256, 512). Спешу расстроить: экспоненциального роста качества модели, увы, не происходит.
Мы выяснили, что лучше выбирать значение ранга 8 или 32. Ранг 8 — золотая середина, но с моделью, у которой изначально было низкое качество или неудачная архитектура, вы, скорее всего, быстро упрётесь в потолок. При ранге 32 модель начинает работать лучше и улавливать более мелкие детали. С дальнейшим увеличением ранга можно увидеть рост метрик, но по субъективным оценкам качество падает: модель начинает цепляться за ошибки в обучающих данных и чаще галлюцинировать.
Обучение LoRA требует от 1000 до 50 000 примеров для обучения. На большем количестве обучающих примеров на наших данных мы не получали роста качества, хотя до этого была очевидная зависимость качества от количества данных.
В случае fine-tune можно обучать модель целиком — full fine-tune. Для больших моделей такой вариант достаточно требователен к ресурсам, поэтому в качестве альтернативы можно обучать только часть слоёв. Обычно это называют «разморозкой»: модель по умолчанию «заморожена» и большинство весов зафиксированы. Если «разморозить» только необходимые слои, обучение будет быстрее, но проблемнее — спрогнозировать, какие слои размораживать, достаточно сложно. Full fine-tune позволяет получить максимальное качество на текущей архитектуре модели, но этот метод более требователен к количеству и качеству данных, чем LoRA и p-tune.
Теперь мы знаем все плюсы и минусы всех подходов — что же выбрать? При малом количестве данных использование fine-tune приведёт к тому, что модель будет более подвержена prompt injection — исходя из наших наблюдений, с LoRA такое случается реже. В то же время при fine-tune потенциал качества выше — модель начинает улавливать больше интересных деталей. Кстати, это одновременно и плюс, и минус: при недостаточно качественном датасете модель обязательно научится чему-то плохому даже из всего лишь из пары примеров. В случае с LoRA с рангом 8 или 32 есть шанс, что такого не произойдёт. Однако, если есть идеальный датасет, то full fine-tune даст наибольшее качество.
Для нас LoRa оказался эффективным препродакшн-инструментом для проведения множества экспериментов при подготовке датасета и проверке гипотез. Это метод позволяет быстро и дёшево исследовать различные подходы и идеи, не тратя много времени и ресурсов. Однако мы понимаем, что LoRa — неидеальное решение. Поэтому после того, как мы упираемся в потолок качества, переход на fine-tune даёт нам рост в качестве за счёт того, что у нас есть хорошо подготовленный качественный датасет.
В целом сочетание LoRa и fine-tune позволяет нам эффективно использовать преимущества обоих методов для достижения лучших результатов. Такой подход мы применили для суммаризации страниц, и аналогичный подход применялся для пересказа видео.
Обучение модели
Поняв, что мы хотим, приступили к этапу обучения. В первую очередь нужно понять, как и на чём мы будем обучать модель. Мы подготовили порядка 20 000 суммаризаций видео в уже утверждённом нами формате (за что огромное спасибо асессорам).
{Заголовок} {Таймкод} {Тезисы для части} {Заголовок} {Таймкод} {Тезисы для части} {Заголовок} {Таймкод} {Тезисы для части}
Для каждого видео у нас были субтитры как input и суммаризация в нужном формате как target. Внимательный читатель заметит, что такой формат требует от модели решать сразу две задачи: чаптеризацию (разделения текста на части) и суммаризацию. Для нас такой вариант оказался оптимальным, так как YandexGPT, как и почти любая большая языковая модель, способна решать несколько задач одновременно.
Вообще, YandexGPT — это семейство нейросетевых моделей разного размера. Для нас была важна скорость работы: когда пользователь нажимает кнопку, результат должен появляться почти без ожидания. Так было с суммаризацией статей, так должно происходить и в случае видео. Учитывая такие вводные, мы остановились на инференсе small-версии модели. Это почти золотая середина между скоростью и качеством. Кроме того, у неё есть специализации, отдельно подготовленные версии:
-
базовая модель сразу после претрейна;
-
базовая модель, дообученная на разных командах и базовых инструкциях;
-
aligned — instruct-модель, дообученная на ещё большем количестве разных данных, которая способна этично вести диалог и выполнять широкий спектр различных специфических задач.
В целом модели, обученные на instruct-задачах, более подвержены prompt injection, чем модели, просто прошедшие претрейн. Это одна из причин, по которой мы дообучаем базовые модели, вышедшие сразу после претрейна.
Вернёмся к нашей задаче. Когда у тебя на руках 20 000 примеров для обучения, лучший подход для первой итерации — обучить модель на всех и посмотреть, что получится. И в целом это заработало: мы получили самую примитивную модель, от которой было легче двигаться дальше, улучшая среднее качество датасета.
Для оценки моделей в первую очередь мы используем ручную разметку. Это крайне трудозатратный процесс, но так получается детектировать проблемы, которые крайне сложно найти классическими метриками. К этим оценкам выставляются сложные продуктовые требования и на их основе принимается решение о выкатке в прод той или иной модели.
Отправив первую модель на разметку, мы можем получить фидбэк и потом двигаться дальше с бо́льшим пониманием происходящего. Это понимание выражается в том, что мы создаём эвристики для оценки качества. Они обычно ищут криты — ошибки или фразы, которые начинают бесить при чтении суммаризации. Это позволяет валидировать модели перед отправкой в ручную разметку: если количество критов увеличивается ещё на этапе эксперимента, то, вероятно, модель с браком, поэтому размечать её нет смысла.
Сейчас у нас следующий список критов:
-
дублирование начала у тезисов;
-
дублирование окончания у тезисов;
-
дублирование самого тезиса;
-
отсутствие тезисов у чаптера;
-
слишком маленький чаптер (меньше 50 секунд);
-
слишком большой чаптер (больше 10 минут);
-
чаптер вышел за границы таймкодов (само наличие конкретного таймкода не проверяется — только максимальный и минимальный из субтитров);
-
невозрастающий порядок таймкодов у чаптеров;
-
глава больше ожидаемой (при равномерном разбиении).
Но криты — это не единственный способ оценки качества, особенно на первых этапах. У нас есть метрики, по которым мы можем понять уровень качества. Они неидеальны, но по-своему полезны.
Например, в задаче суммаризации можно сравнивать результат с эталоном. В этом могут помочь разные метрики: традиционные BLEU, Rouge или Meteor, а также нейросетевые, например BERTScore. Все традиционные метрики начинают возрастать при увеличении качества модели, но у них есть некоторое оптимальное значение, ниже которого модель считается недоученной, а выше — переобученной. И то и другое видно на ручных разметках. Чем сложнее метрика похожести текстов, тем её значение ближе к оценкам людей.
Отдельно стоят метрики, которые не зависят от наличия некоторого эталонного результата. Например, у нас есть несколько обученных reward-моделей. Первая (и во многом универсальная) оценка суммаризации — SEAHORSE. Она состоит из шести показателей:
-
Q1 comprehensible: понятность. Суммаризация прочитана и понята асессором (если нет, то остальные критерии не оцениваются).
-
Q2 repetition: повторы. Суммаризация не содержит ненужных повторов информации.
-
Q3 grammar: грамматика. Суммаризация не содержит грамматических ошибок.
-
Q4 attribution: соответствие. Суммаризация основана на информации, содержащейся в тексте.
-
Q5 main ideas: основные идеи. Суммаризация передаёт основные идеи текста.
-
Q6 conciseness: лаконичность. Суммаризация кратко представляет информацию, содержащуюся в тексте (интегральная метрика).
Вторая модель — это специализированный под конкретную задачу reward, разный для суммаризации статей и видео. Его можно получить только из ручных разметок. Кроме того, он более полезный, а качество у него выше, чем у SEAHORSE.
За всё время подготовки моделей мы провели 51 гипотезу. Из них мы разметили 27 моделей. А ещё после нескольких итераций обучения и оценки часть датасета мы забраковали: осталось всего 7500 суммаризаций из 20 000 изначальных. Из этого количества мы получили продовую модель — базис, который можно улучшать и дополнять.
Стоит заметить, что учатся модели на неидеальных субтитрах, поэтому местами модель сама догадывается о корректном написании. По своей сути это чем-то похоже на естественную аугментацию текста, но бывают ситуации, когда субтитры сильно сбоят. Например, если смотреть видео на тему GPT4, в субтитрах может проскочить «G пяти четыре». От таких ситуаций мы не застрахованы, и это бьёт по качеству суммаризации, но подобные ошибки постепенно исправляются.
Обработка длинных видео
Ещё на этапе экспериментов на статьях мы заметили, что наша дообученная версия языковой модели наиболее качественно работает в пределах 20 000 символов для суммаризации статей, деградация начинается с примерно 12 000, а дальше по нарастающей. Так мы сошлись на том, что 12 000 символов для суммаризации видео — вероятный предел.
Так как заставить влезть то, что не влезает? Для статей мы выработали две гипотезы, как суммаризировать длинные тексты:
-
Независимое окно. Просто бьём текст на чанки (тут мы попробовали как перекрёстный вариант, так и обычный) и подаём в модель по отдельности независимо друг от друга.

-
Итеративный метод. Также бьём текст на чанки, как на предыдущем варианте, но дополнительно подаём для следующей суммаризации результат из предыдущей итерации.
По итогам проверок оказалось, что качество итеративного варианта выше, но его сложнее обучать. При этом от галлюцинаций в предыдущей итерации начинают страдать следующие суммаризации. Независимое окно показало себя хуже: оно теряет контекст. Но при этом у него есть и плюсы: можно суммаризировать чанки независимо друг от друга.
Но это всё для статей. В случае суммаризации видео мы получили менее депрессивные результаты для независимого окна. Видимо, это особенность формата: нить повествования проще и более структурирована, что позволяет суммаризировать независимые куски видео почти без потерь.
В итоге мы решили разбивать субтитры на равномерные части примерно по 12 000 символов. Далее мы отправляем на суммаризацию каждую часть, а итоги склеиваем. Вполне рабочий вариант, который не требует какой-то особой логики. Однако минусы были: у нас появился артефакт, с которым сейчас активно боремся, — введение и заключение в середине суммаризации. Таких суммаризаций, по нашим замерам, порядка 10%.
Есть ещё один момент, на который стоит обратить внимание: слепое разделение субтитров по 12 000 символов может привести к тому, что мысль спикера оборвётся где-то посередине, что сказывается на качестве. Эту проблему мы решили отдельной моделью чаптеризации, которую подготовили коллеги из ASR-пайплайна. Она обучена как классификатор смены темы и позволяет бить текст на независимые куски, не теряя мысль где-то на середине.
При обучении этой модели в качестве начальной точки мы взяли другую модель, которую обучили уже другие наши коллеги из видеопоиска: после ASR и определения биометрии дополнительно прогонялась BERT-подобная сеть над распознанными текстами для предсказания точек смены темы. После этого над выхлопами всех трёх сетей получаем единый ответ бустингом. Задачу формализовали как бинарную классификацию «была или не была смена темы» для последовательных пар предложений. В данном случае модель училась на видео с авторской разметкой и дополнительно использовала свой доразмеченный датасет.
Проблема в том, что в задаче пересказа видео as-is такое решение было неудобно: мы очень хотели как можно быстрее давать ответ пользователю, а запуск дополнительной сети излишне затягивал процесс пересказа. Но мы учли, что модель суммаризации сама способна выделять темы, и раз у нас есть «крепкая» сетка для суммаризации, то можно дистиллировать вышеописанную конструкцию во что-то более быстрое — выбор пал на CatBoost.
Но для CatBoost требуется несколько иной формат входных данных, нужно выделить достаточно минималистичный табличный набор параметров, по которым модель сможет предсказывать смену темы. Вот основной набор параметров, на которых обучался классификатор:
-
длина паузы от последнего предложения;
-
косинус между эмбеддингами голосов спикеров текущего и предыдущего предложений;
-
смена ID спикера;
-
смена пола спикера.
Были ещё другие легковычисляемые фичи, которые мы, по сути, просто собрали вместе. При замере финального качества оказалось, что нет большой разницы в метриках суммаризационной модели на чанках, разбитых большой BERT-моделью, и маленького CatBoost поверх выхода ASR и биометрии.
Таким образом, в суммаризацию приходят чаптеры, которые мы подготавливаем и склеиваем в чанки (parts) в пределах 12 000 символов.
Не моделькой единой
Нажав кнопку суммаризации, можно заметить, что всё отрабатывает почти моментально. Если это так, то вам повезло: вы попали в кеш, где все данные сохранены.
А если данных в кеше нет? В таком случае мы используем субтитры платформы, на которой расположено видео — автосубтитры. Мы подготавливаем их и отсылаем в модель. Суммарно этот процесс занимает около 5 секунд. Но у автосубтитров есть проблемы: их может попросту не быть, а когда они есть, то бывают низкого качества (даже человек не всегда может всё идеально понять, какая уж модель).
В момент, когда пользователь впервые запросил суммаризацию, мы работаем с автосубтитрами, но при этом параллельно запускаем собственный процесс ASR для получения качественных субтитров. Да, это дольше и какое-то время пользователи будут видеть «черновую» суммаризацию. Однако когда мы получим результат от нашего ASR, то заменяем суммаризацию в кеше на новую, сделанную на более качественных субтитрах.
Целиком пайплайн выглядит так:

Стоит упомянуть, что не все видео прошли подобный путь. Отдельно у нас припасён фоновый процесс, который заранее обработал популярные каналы и сложил суммаризации в кеш, чтобы на старте мы не упали под нагрузкой.
Пересказ видео — это сложная комплексная задача. Мы продолжаем улучшать качество пересказов, а ещё в наших планах движение в сторону поддержки нескольких спикеров, что особенно актуально в разного рода интервью и разговорных видео с несколькими участниками.
Суммаризация работает в десктопной и мобильной версиях Яндекс Браузера. Просто нажмите кнопку «Пересказать», которая появляется в окне с видео. Вне Браузера пересказать видео и статьи поможет 300.ya.ru.
Теги:
- яндекс
- яндекс.браузер
- пересказ
- yagpt
- видео
- llm
- yalm
Хабы:
- Блог компании Яндекс
- Браузеры
- Машинное обучение
- Искусственный интеллект
- Natural Language Processing
Если эта публикация вас вдохновила и вы хотите поддержать автора — не стесняйтесь нажать на кнопку Задонатить
![]()